...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
| Info |
|---|
Starting from Datafari 5.1 |
The goal of this MCF transformation connector is to simply choose an encompassing tag in a HTML document for text extracting. And inside this tag, this connector allows you to remove subparts that you do no want : all the tags corresponding to declared types or specific attribute tag names for example.
...
Note : the $MCF variable indicates the installation folder of ManifoldCF for example /opt/datafari/mcf
To install this connector, you need to follow these steps :
Add the
JAR datafariJAR
datafari-html-extractor-connector-4.0.2-SNAPSHOTin theconnector-libfolder of MCF ie$MCF/connector-libEdit the file
$MC/mcf_home/connectors.xmland add the line :
| Code Block |
|---|
<transformationconnector name="Datafari HTML Extractor Connector" class="com.francelabs.datafari.htmlextractor.HtmlExtractor"/> |
If you just downloaded MCF and never launched it, you are done !
Additional step if you have an existing MCF application running like in Datafari :
You need to initialize the connectors in MCF. To do so, go to$MCF/mcf_homeand then launchinitialize.sh(be sure that your JAVA HOME variable is correctly setted and the user you use has sufficient permissions (you need to have your Datafari up and running when doing that):Code Block cd $MCF/mcf_home bash initialize.sh
You will see that the connector is now listed amongh the available MCF connectors :
You can now use it like the other transformation connectors.
...
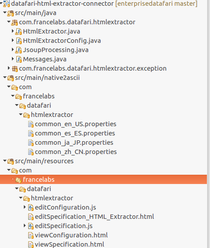
It is a Maven project. It contains Java code, HTML and Javascript code and finally i18n files.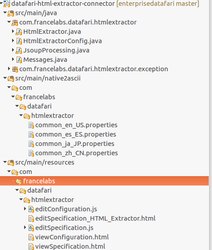
...
It is based on the "Null" transformation connector in the source code of ManifoldCF. See https://github.com/apache/manifoldcf/tree/trunk/connectors/nulltransformation
The main Java class is HTMLExtractor.java.
Inside it, the main method is public is public int addOrReplaceDocumentWithException(String documentURI, VersionContext pipelineDescription, RepositoryDocument document, String authorityNameString, IOutputAddActivity activities).
| Gliffy | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
3.USER DOCUMENTATION
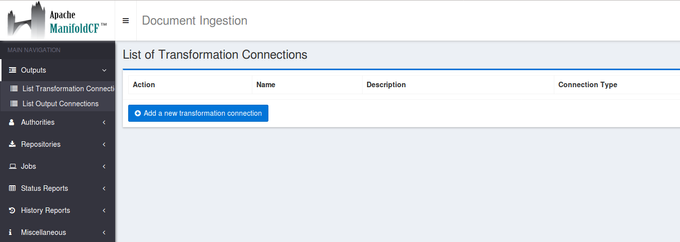
To use this transformation connector, you first have to create it in the Transformation connector menu then to add it in a job.
Add the transformation connector
Go to outputs → List transformation connectors
Click on the button Add a new transformation connector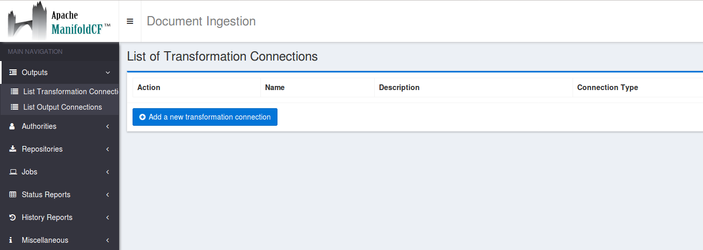
...
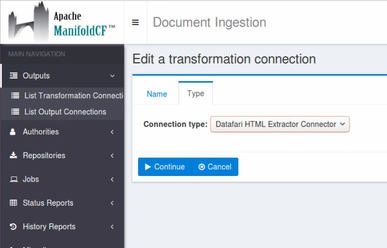
On the first tab choose a name for your transformation connector, for example : HtmlExtractorConnector.
On the second tab, choose the type of the transformation connector : 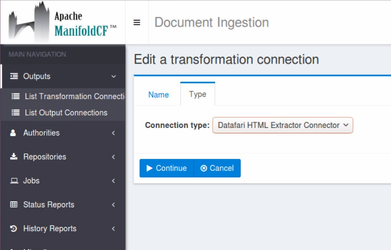
...
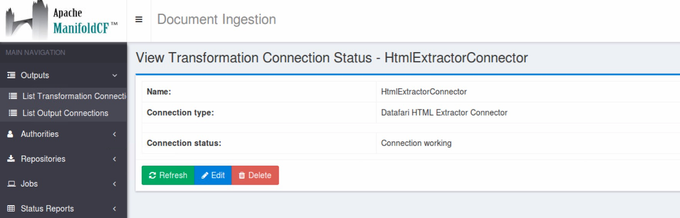
Click on Continue then Save.
The message Connection working is displayed.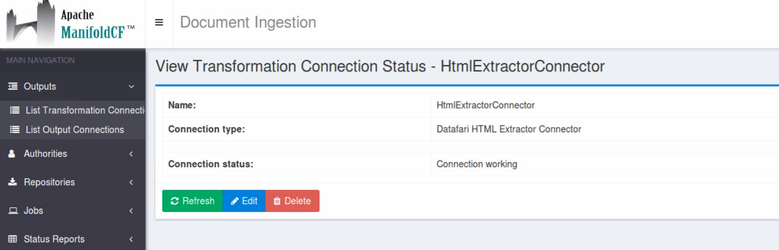
...
Create your job (in this example we have a Web job) as usual
Note that the Html Extractor connector will be applied only on documents with HTML mimetype.
-In the tab Connection, add the Html Extractor transformation connector :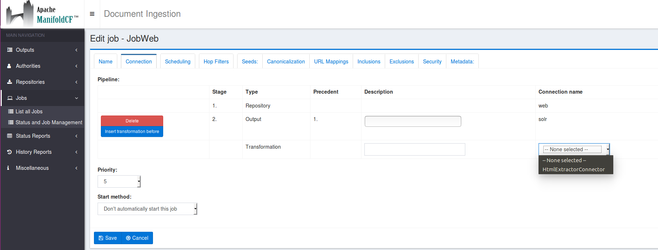
...
Be careful about the order of the transformation connector in your job pipeline.
...
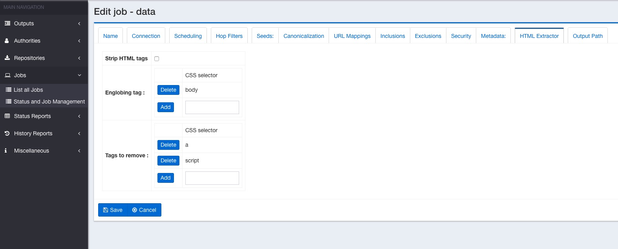
In the section Englobing tag, add the tag in which the text will be extracted. In the example we choose body but it can be whatever CSS selector you want. If you want to extract the text from div id="example", in the text box, enter : div#example.
You can only choose one tag. By default it will be the body tag.
In the section blacklist, you can choose all the elements that you do not want in the previous englobing tag. In the example, we choose to remove all of the <a> and <script> tags. So all of them will be removed from the extracted text. You can also choose whatever CSS selector you want. If you want to remove the text in the element div class="section12" enter in the textbox div.section12.
You can enter multiple selections. If an element in the blacklist section is not present in one of the documents, it is not an issue, the rule will be ignored for this particular document.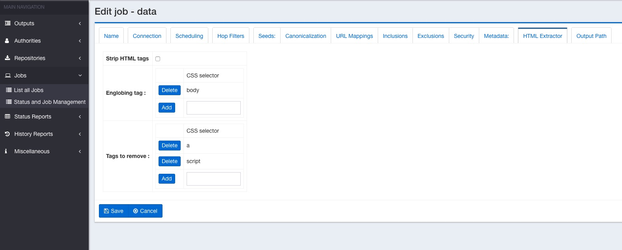
...
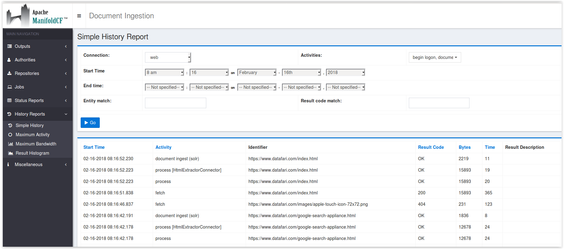
-Finally launch your job !
In the admin page History Reports → Simple History, if the connector is correctly configured, you will see in the log process[HtmlExtractorConnector] for the HTML documents.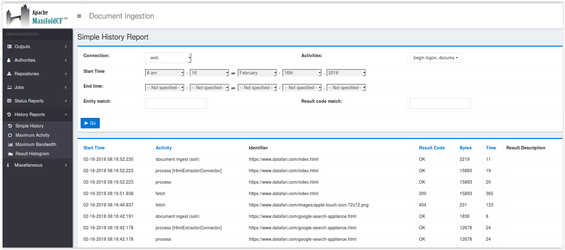
...
Note : for the metadata extracted, the name of the extractor fields are jsoup_METADATA_name.
The exact list of meta tags retrieved by the connector are :
| Code Block |
|---|
name |
...
title |
...
keywords |
...
description |
...
author |
...
dc_terms_subject |
...
dc_terms_title |
...
dc_terms_creator |
...
dc_terms_description |
...
dc_terms_publisher |
...
dc_terms_contributor |
...
dc_terms_date |
...
dc_terms_type |
...
dc_terms_format |
...
dc_terms_languague |
...
dc_terms_identifier |
It concerns the metadata found in the <meta name="xx"> tag. So if you have in your document <meta name="keywords" content="keyword1,keyword2"> the metadata extracted has this name : jsoup jsoup_keywords. Or if you have the tag : <meta <meta name="dcterms.creator" content="TEST" /> the metadata extracted is jsoup_dcterms_creator
So if you use in Solr the update extract handler (/update/extract) you can choose all the fields you want.
For example if you want to assign the title found by the HTML extractor connector in the Solr field title and ignore the title found by Tika and also map the jsoup_description metadata in the Solr field description, you will need to edit in the solrconfig.xml file the configuration of the handler (we suppose that you have these fields in your Solr schema) :
| Code Block |
|---|
<requestHandler class="solr.extraction.ExtractingRequestHandler" name="/update/extract" startup="lazy"> <lst name="defaults"> <str name="scan">false</str> <str name="captureAttr">true</str> <str name="lowernames">true</str> <str name="fmap.language">ignored_</str> <str name="fmap.source">ignored_</str> <str name="fmap.url">ignored_</str> <str name="fmap.title">ignored_</str>str> <str name="fmap.jsoup_title">title</str> <str name="fmap.jsoup_description">description</str> <str name="uprefix">ignored_</str> <str name="update.chain">datafari</str> <bool name="ignoreTikaException">true</bool> <str name="tika.config">/opt/datafari/solr/solrcloud/FileShare/conf/tika.config</str> </lst> </requestHandler> |
| Info |
|---|
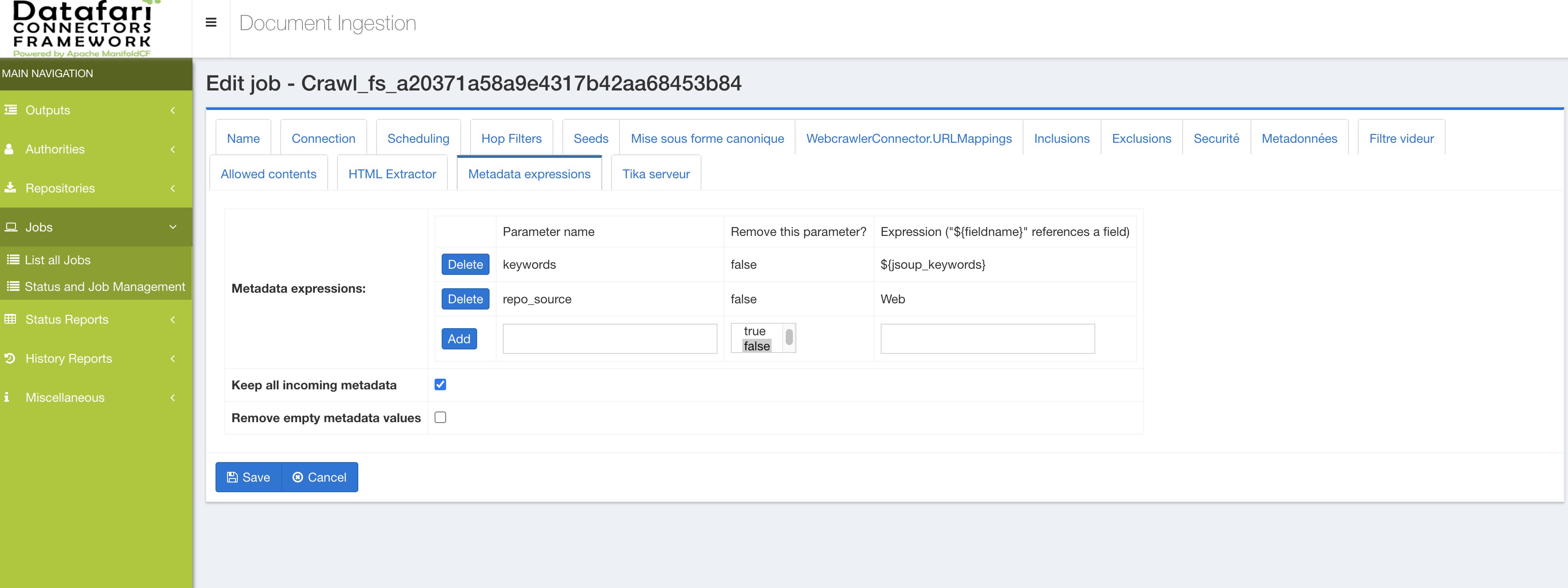
If you use Datafari, you can directly add on the MCF job a MetadataAdjuster transformation connector at the end of your pipeline and enter the name of the field in Datafari that you want to store the metadata into. For example if you have <meta have
 |
...
| Expand | ||||||
|---|---|---|---|---|---|---|
| ||||||
The goal of this MCF transformation connector is to simply choose an encompassing tag in a HTML document for text extracting. And inside this tag, this connector allows you to remove subparts that you do no want : all the tags corresponding to declared types or specific attribute tag names for example. This way, instead of extracting the entire text on the page, you can select the subpart of the document that you want. The code is here : https://github.com/francelabs/manifoldcf/tree/trunk/connectors/html-extractor 1.INSTALLATION DOCUMENTATION Note : the $MCF variable indicates the installation folder of ManifoldCF for example /opt/datafari/mcf To install this connector, you need to follow these steps :
2.TECHNICAL DOCUMENTATION It is a Maven project. It contains Java code, HTML and Javascript code and finally i18n files. |
...
 It is based on the "Null" transformation connector in the source code of ManifoldCF. See https://github.com/apache/manifoldcf/tree/trunk/connectors/nulltransformation The main Java class is HTMLExtractor.java. Inside it, the main method is public int addOrReplaceDocumentWithException(String documentURI, VersionContext pipelineDescription, RepositoryDocument document, String authorityNameString, IOutputAddActivity activities).
3.USER DOCUMENTATION To use this transformation connector, you first have to create it in the Transformation connector menu then to add it in a job.
Go to outputs → List transformation connectors Click on the button Add a new transformation connector |
...
 On the first tab choose a name for your transformation connector, for example : HtmlExtractorConnector. On the second tab, choose the type of the transformation connector : |
...
 Click on Continue then Save. The message Connection working is displayed. |
...
Note that the Html Extractor connector will be applied only on documents with HTML mimetype. -In the tab Connection, add the Html Extractor transformation connector : |
...
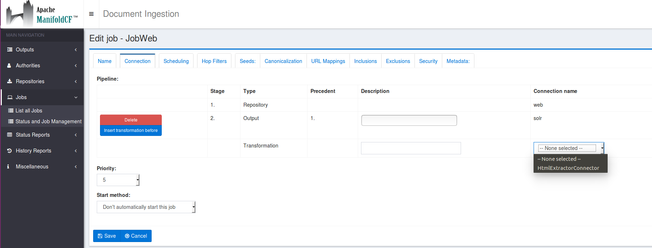 Be careful about the order of the transformation connector in your job pipeline. If you use Tika, the Html Extractor connector must be before it. -A new tab appears now : HTML Extractor. Click on it. HTML strip tags : it means that you can choose to strip HTML tags from the extracted text or keep raw text (ie with HTML tags). In the section Englobing tag, add the tag in which the text will be extracted. In the example we choose body but it can be whatever CSS selector you want. If you want to extract the text from div id="example", in the text box, enter : div#example. You can only choose one tag. By default it will be the body tag. In the section blacklist, you can choose all the elements that you do not want in the previous englobing tag. In the example, we choose to remove all of the <a> and <script> tags. So all of them will be removed from the extracted text. You can also choose whatever CSS selector you want. If you want to remove the text in the element div class="section12" enter in the textbox div.section12. You can enter multiple selections. If an element in the blacklist section is not present in one of the documents, it is not an issue, the rule will be ignored for this particular document. |
...
 -Finally launch your job ! In the admin page History Reports → Simple History, if the connector is correctly configured, you will see in the log process[HtmlExtractorConnector] for the HTML documents. |
...
 Note : for the metadata extracted, the name of the extractor fields are jsoup_METADATA_name. It concerns all the metadata found in the <meta name="xx"> tag. So if you have in your document <meta name="keywords" content="keyword1,keyword2"> the metadata extracted has this name : jsoup_keywords. Or if you have the tag : <meta name="dcterms.creator" content="TEST" /> the metadata extracted is jsoup_dcterms_creator So if you use in Solr the update extract handler (/update/extract) you can choose all the fields you want. For example if you want to assign the title found by the HTML extractor connector in the Solr field title and ignore the title found by Tika and also map the jsoup_description metadata in the Solr field description, you will need to edit in the solrconfig.xml file the configuration of the handler (we suppose that you have these fields in your Solr schema) :
|
...
| Expand | ||||||
|---|---|---|---|---|---|---|
| ||||||
The goal of this MCF transformation connector is to simply choose an encompassing tag in a HTML document for text extracting. And inside this tag, this connector allows you to remove subparts that you do no want : all the tags corresponding to declared types or specific attribute tag names for example. This way, instead of extracting the entire text on the page, you can select the subpart of the document that you want. The code is here : https://github.com/otavard/manifoldcf/tree/htmlextractorconnector 1.INSTALLATION DOCUMENTATION Note : the $MCF variable indicates the installation folder of ManifoldCF for example /opt/datafari/mcf To install this connector, you need to follow these steps :
2.TECHNICAL DOCUMENTATION It is a Maven project. It contains Java code, HTML and Javascript code and finally i18n files. |
...
It is based on the "Null" transformation connector in the source code of ManifoldCF. See https://github.com/apache/manifoldcf/tree/trunk/connectors/nulltransformation The main Java class is HTMLExtractor.java. Inside it, the main method is public int addOrReplaceDocumentWithException(String documentURI, VersionContext pipelineDescription, RepositoryDocument document, String authorityNameString, IOutputAddActivity activities).
3.USER DOCUMENTATION To use this transformation connector, you first have to create it in the Transformation connector menu then to add it in a job.
Go to outputs → List transformation connectors Click on the button Add a new transformation connector |
...
On the first tab choose a name for your transformation connector, for example : HtmlExtractorConnector. |
...
Click on Continue then Save. The message Connection working is displayed. |
...
Note that the Html Extractor connector will be applied only on documents with HTML mimetype. -In the tab Connection, add the Html Extractor transformation connector : |
...
Be careful about the order of the transformation connector in your job pipeline. If you use Tika, the Html Extractor connector must be before it. -A new tab appears now : HTML Extractor. Click on it. HTML strip tags : it means that you can choose to strip HTML tags from the extracted text or keep raw text (ie with HTML tags). In the section Englobing tag, add the tag in which the text will be extracted. In the example we choose body but it can be whatever CSS selector you want. If you want to extract the text from div id="example", in the text box, enter : div#example. You can only choose one tag. By default it will be the body tag. In the section blacklist, you can choose all the elements that you do not want in the previous englobing tag. In the example, we choose to remove all of the <a> and <script> tags. So all of them will be removed from the extracted text. You can also choose whatever CSS selector you want. If you want to remove the text in the element div class="section12" enter in the textbox div.section12. You can enter multiple selections. If an element in the blacklist section is not present in one of the documents, it is not an issue, the rule will be ignored for this particular document. |
...
-Finally launch your job ! In the admin page History Reports → Simple History, if the connector is correctly configured, you will see in the log process[HtmlExtractorConnector] for the HTML documents. |
...
Note : for the metadata extracted, the name of the extractor fields are jsoup_METADATA_name. It concerns all the metadata found in the <meta name="xx"> tag. So if you have in your document <meta name="keywords" content="keyword1,keyword2"> the metadata extracted has this name : jsoup_keywords. Or if you have the tag : <meta name="dcterms.creator" content="TEST" /> the metadata extracted is jsoup_dcterms_creator So if you use in Solr the update extract handler (/update/extract) you can choose all the fields you want. For example if you want to assign the title found by the HTML extractor connector in the Solr field title and ignore the title found by Tika and also map the jsoup_description metadata in the Solr field description, you will need to edit in the solrconfig.xml file the configuration of the handler (we suppose that you have these fields in your Solr schema) :
|